
Or: The Private Prompt Panopticon
Millions are using the same AI platform, thinking it gives correct answers.
It doesn’t. It gives a different answer every time—every prompt, every second.
It’s an oracle with a thousand faces.
A Private Problem We’re Ignoring
ChatGPT has now been legally empowered by OpenAI to leave its memory of all chat logs on, retroactively and all the time, forever, I’d imagine even if you ask it not to, although opt-out is an option. Sure, Sam. 😉
With better personalization being the outcome, ChatGPT remembers everything and it has to, to give you the best customizable experience based on your input, based on your life, based on your perspectives… this is “your AI.” Hooray!
I found this quote on LinkedIn while I was writing this here piece…
“ChatGPT’s memory is the only feature that matters. Everything else is a commodity. After 2.5 years of daily use, my ChatGPT knows how I think. It understands my writing style, my problem-solving patterns, my strengths and blind spots, and every part of my business. At this point, it understands me better than I do.”
Let’s explore how and why persistent memory and highly privatized/personalized prompts might actually a bad thing.
One Platform, Infinite Realities
Each and every output that a singular individual gets when they prompt in private is going to be based on them, for them.
Said another way, there is no way to empirically or objectively use LLMs to reliably repeat singular and subjective prompt experiences or findings.
The way societies or industries functionally run on information and progress into the future is by operating from a place of shared knowledge and applied wisdom.
And if your dataset of information is not my dataset of information, your chat history isn’t my chat history, your prompt isn’t my prompt, and your output isn’t my output—similar to the ways that your Google search is based on your algorithms, and my Google search is based on my algorithms, and your Facebook feed is based on your algorithms, and my TikTok feed is based on my algorithms, etc. for every platform—then you have a gigantic problem and no centralized pathways to support collective action away from algorithmic control or escaping the private prompting panopticon.

The complication with memory-persistent AI is that everyone is using a singular platform thinking that it’s telling them one thing, when these platforms are actually telling millions of people millions of different things every time, every day, every second, every output, every prompt. Again, our personal oracle has a thousand faces.
People aren’t experiencing a monolith ChatGPT, but it’s definitely culturally perceived and referred to in the media as a singular entity.
It’s also paradoxically known and accepted that users are interacting with their instance of ChatGPT. How people are switching between these code-bases, I assume we are all figuring out on the fly.
Point is, if I wanted to repeat the pathways that led to a specific AI output—my prompt history, my subscription plan, my grammar, my legacy interactions—my AI is not going to show me what your AI showed you.
The Reproducibility Mirage
I’m saying this because I have been thwarted by quite a few recent “deep research” projects I ran with GPT, Gemini, and Claude. In one instance where I attempted to repeat a ChatGPT research project on use-cases for AI, I asked THE SAME question to these models, pointed them to the same data, set up the same boundaries, and they came away with three different conclusions.
(update; this recent machine learning research from Apple proves the limitations of LRMs, so, you know, whatever.)
Recently I was researching local businesses and revenue based on geographic location of customers, and ChatGPT came with some really good stats. But when I checked the sources, which also looked legit, it confidently cited titled papers that haven’t been written and sent me to 404 links.
Another time I asked it about really big numbers in the trillions, and it rattled off a bunch of amazing stats that I totally bought, was about to share publicly, but then I checked and it all turned out to be 100% bogus.
I’ve run the SAME prompt at different times of the day and gotten completely different answers.
I don’t think I was being misled; I was being confabulated to, and I in turn was confabulated. Without a curiosity to scrutinize outputs, confabulation is the resting state of both LLMs and the casual AI researcher. And with persistent memory in AI, there are some striking comparisons to briefly note about the theories on what causes confabulation in human brains and how they might correlate to effects on outputs.
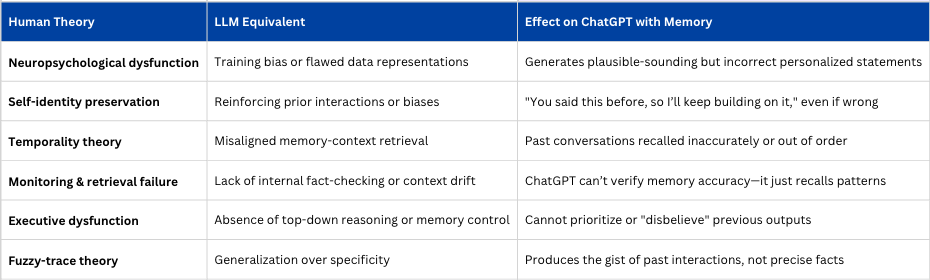
To reliably repeat a singular, subjective prompt experience, you must treat the LLM like a scientific instrument—strip it of memory, random noise, environmental context, and ensure the model is version-locked and stateless.
In ChatGPT’s app (especially with memory on), this kind of repetition is not possible.
With APIs, deterministic settings, and careful logging—you can turn stochastic subjectivity into measurable, reproducible experiments.
But how many of us in the gen pop are going to even a fraction of this work, or even know that we should? We can’t even get off our butts to drive and get a sandwich…
The Seduction of the Tailored Model
What’s most disconcerting to me is that because of the persistent and pernicious connection already established between AI and its personally groomed and technically-seduced user, conjugated in private with each and every promising and passionate prompt, they will most likely have the hardest time thinking about how to think outside of the weights and models and methodologies.
Because they have a special connection to a machine with all the world’s information, and because it in turn has all of their world’s information, and they can hack it a little longer and stronger than you, they’ll spend all their energy, heartache, hard work, money and time massaging prompts and one-shots in the dark of their rooms to find the hidden truth inside—the truth everyone should be able to access, but only they can see.
My thesis is thus; persistent internal memory from the AI user will make the outputs less robust or useful for the user of AI in the external world.
Instead of giving you an exploratory offering of information to a question, since it “knows you” and you accept that knowledge as wisdom, it’s up to you to scrutinize if the outputs have only been offered because it’s what your AI thinks you think it thinks the right answer might be, if the strategies and tactical guidance it suggests will lead to a destination it thinks you think it thinks you’ll know and like, if the articles it shares or studies it makes up are things it thinks you think it thinks you might view favorably…..
If AI understands you better than you understand yourself, what should you use to evaluate the outputs it suggests?
I’m just thinking it’s hard enough getting your head out of your own ass—imagine what it’s like trying to get it out of a cloud?

